-
May 28, 2026
- Share:
-

-

-

-


Bad test data doesn’t announce itself.
You pass the suite. You ship. Something breaks in production that your tests should have caught.
You dig in and find the issue wasn’t the code. The test environment didn’t have the right data to expose it in the first place. This happens in QA teams every week, at every scale, in every industry.
AI-driven test data generation is the most practical fix for this problem.
The Evolution of Test Data Generation
The first era was all about “copy production, hide the names, hope for the best”. A DBA would run a masking script against a production snapshot, swap out email addresses and social security numbers, and drop the result in the shared test environment.
It worked until GDPR made it a liability. Also, a scrubbed copy of production data reflects the state of production on the day you took the snapshot. Schema changes, new product types, and updated business rules are all missing.
The second era was all about rules. Tools like Faker and Mockaroo let you define constraints and generate synthetic records. For example, you’d specify that:
- account_status could be “active,” “suspended,” or “pending,”
- order_total had to be a positive float under 99999.99
- customer_id had to be a valid foreign key in the customers table.
The tool generated rows that satisfied those constraints. This was better, but it was also brittle because the rules only knew what you told them.
Example:
Your schema says order_total is a positive float.
It says nothing about the fact that orders over $10,000 from accounts created in the last 30 days get routed to a fraud review queue, which locks the account. That means any automated fulfillment process will hang waiting for manual approval.
That logic lives in a Confluence page nobody has updated since 2022. When you generate test data using only schema rules, you get records that will never trigger the fraud queue.
Your fulfillment tests pass. The bug in the fraud queue handling never appears. It surfaces later, in production, when a real order from a new customer crosses $10,000.
The third era is the AI-driven generation. AI models don’t need testers to specify rules. They analyze existing data and learn what it does.
For example, in your production system, large orders from new accounts trigger a specific account status sequence. The AI sees that pattern and generates records that include it. You didn’t have to write a rule for it because the AI model could read the existing pattern and create the necessary test.
Discover Top 8 Test Automation Features of 2026
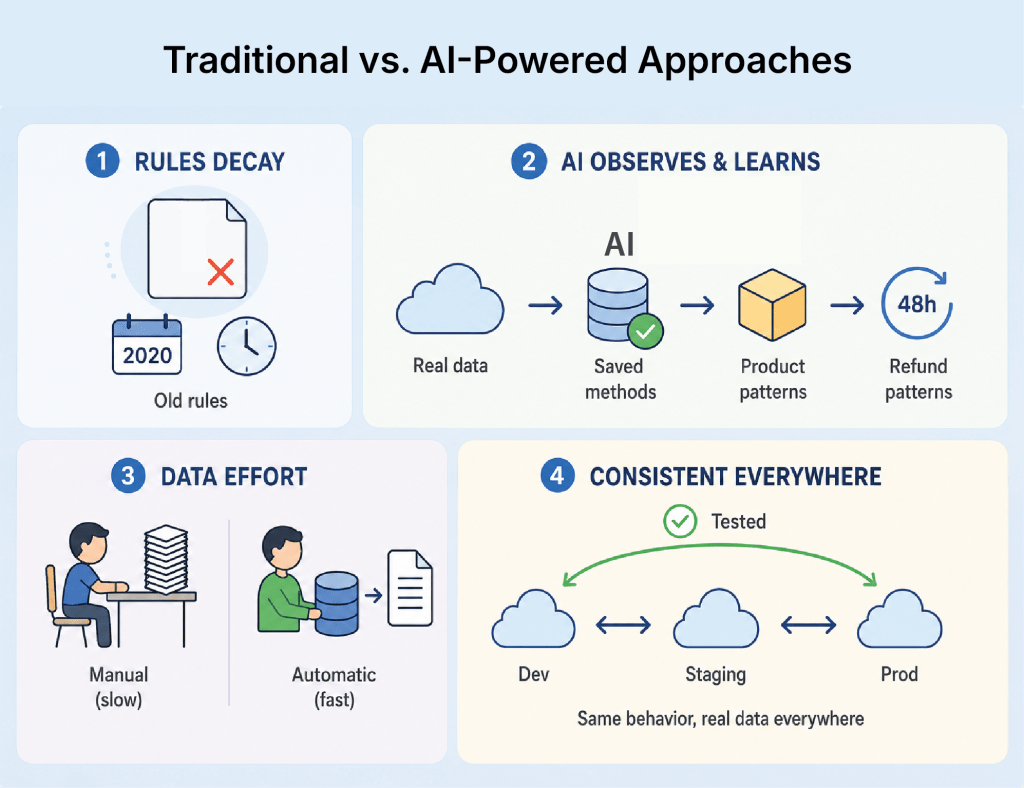
Traditional vs. AI-Powered Approaches
Rules decay.
Let’s say, a payment processing system that handled simple card transactions in 2020 now handles buy-now-pay-later plans, crypto settlements, and split payments across multiple funding sources.
The test rules written in 2020 produce data that reflects none of those. Someone should have updated them, but nobody did.
AI-powered generation observes the current state of your data rather than depending on rules. Feed it a production sample (anonymized for compliance), and it builds a statistical model of how your fields actually co-vary.
The model learns that premium-tier customers tend to have between three and seven saved payment methods. That cancelled subscriptions in the system almost always have a corresponding refund record within 48 hours. The product catalog has roughly 2% of SKUs with null weight fields, because they are digital products, and those nulls appear alongside a specific digital_delivery flag.
None of this exists in your schema. An AI-driven generator will, for instance, put nulls where they actually belong (digital products) because that is the pattern in your real data.
Rule-based generation produces valid data. AI-driven generation produces realistic data.
Faster Data Creation for Automated Testing
The actual bottleneck in most test cycles starts with getting the data the tests need to run.
Another example.
A senior engineer on a payments team spends half a day constructing a dataset that represents a customer who has an active subscription, a failed payment from the last billing cycle, a pending dispute, and a recently added backup payment method.
That’s four tables, specific status combinations, and timestamp relationships that have to be internally consistent. If she gets any of it wrong, the test gives a misleading result. If she leaves the company, nobody knows how to reconstruct it.
AI-driven generation manages these with plain-language descriptions. The tester specifies the scenario in regular language. The system generates records across all required tables with the right status combinations and timestamp relationships in under a minute.
TestWheel integrates data generation directly into the test pipeline. When a test definition changes, the associated data profile updates automatically on the next run. A team moving from two-week releases to daily deployments cannot afford to run manual data setup before each cycle. TestWheel gets it done in the background.
Multi-environment consistency also becomes achievable. A dataset that behaves correctly in the dev environment but was provisioned differently in staging often leads to “it works on my machine” failures in QA.
When generation is centralized and parameterized, the same behavioral profile produces environment-appropriate data everywhere. The records have different IDs and timestamps per environment, but the relationships and status combinations are identical.
A bug that appears in staging now appears in dev, too.
Improving Edge-Case and Regression Coverage
The edge cases that reach production share a pattern. They require a specific combination of conditions that each seems basic individually.
For example, a user with a free trial account that converted to paid on the last day of the month, in a timezone where that is already the first of the next month on the server. Or, a product returned for a refund after the original payment method was removed from the account.
Each of those conditions appears in your production data, but not in test data generated from rules written without those scenarios in mind.
An AI model trained on production patterns finds them because they are statistically present in the data, even if they are rare.
Regression testing has a different problem. Shared test environments accumulate data drift. A developer runs a test that updates a customer’s subscription status. The test passes, but the record stays updated.
Another test later in the day assumes that the customer has the original status. It gets an unexpected result. Someone opens a bug ticket. Someone else traces it to the shared record and manually resets it.
Now, two other tests that ran against the modified record have already been marked as ‘passing’. They should not have been.
TestWheel solves this by treating each regression run as a clean-room environment. Before the suite runs, the data is regenerated from scratch. A failure means the code behaved differently than expected. You can rule out the possibility that a previous test left the environment in a different condition than the current test assumed.
Challenges with AI-Generated Datasets
AI-generated data can be wrong, and it’s harder to spot than mistakes in manually generated data.
When a human writes a test record incorrectly, the error is usually visible on inspection. You can see a status field set to a value that doesn’t exist in the enum, or a foreign key pointing to a deleted record.
An AI-generated violation? Not as easy. The field values are individually plausible. The schema constraints pass. The problem is in the relationship between fields.
Here are the main challenges you’ll be dealing with when working with AI-generated datasets.
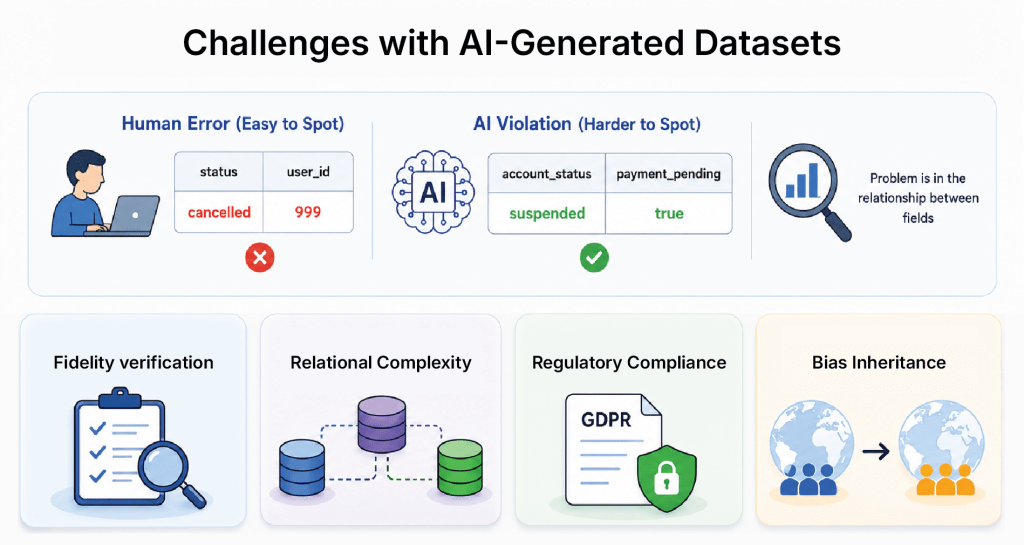
Fidelity Verification
An AI model trained on production data learns that account_status “suspended” and payment_pending “true” rarely appear together. Your system processes pending payments before suspending accounts.
But ‘rarely’ is not never. So, the model generates a small number of records with that combination.
A test that assumes suspended accounts have no pending payments passes against those records. The test is not wrong, but the data made it wrong.
Every AI-generated dataset needs a validation pass against actual business rules, not just inferred patterns. TestWheel validates generated data against your actual business rules, independent of what the model learned. Where output violates a rule, the record is flagged and regenerated. This is how you build trustworthy datasets.
Relational Complexity
Generating consistent data across an order management system with 40 tables, a separate inventory system with 30, and a customer platform with 20 more is not straightforward. Most tools handle it partially at best.
When evaluating vendors, ask specifically what happens at that relational depth. Ask them to demo against a schema with more than 50 tables and foreign keys that cross system boundaries.
Regulatory Compliance
Under GDPR Article 4, synthetic data generated by a model trained on personal data may still constitute personal data if individuals can be re-identified from it. European data protection authorities currently presume that synthetic data derived from personal data remains personal data unless re-identification risk can be demonstrated to be minimal.
If you are in financial services, healthcare, or any regulated sector, involve your data protection officer before building a process that depends on AI-generated synthetic data. You have to consider your jurisdiction, your training data, and the re-identification risk profile.
Bias Inheritance
The model learns from historical production data. If your system was only deployed in North America for its first three years, the generated data reflects North American behavior, address formats, phone patterns, and transactions.
When you expand to Europe and test localization, the AI-generated data will not represent European user patterns as they are not in the training set. You probably won’t notice this until a localization bug reaches production.
Enterprise Use Cases and Scalability
Enterprise-scale testing has a data problem. The cost is distributed across teams in ways that make it hard to pin down on any single budget line.
Cross-System Consistency
A large insurance company running CI/CD across a claims platform, a policy management system, and a billing service needs test data that has to be consistent across all three. A claim has to reference a valid policy. The policy has to reference a valid customer with a valid billing account. The billing account has to have a payment history that matches the policy start date.
Manually maintaining that consistency across three systems with separate teams, schemas, and release cycles is hard work. People often end up maintaining personal spreadsheets of test account IDs they never formally document.
When one team makes a schema change, the consistency is gone. Someone discovers it when a cross-system integration test fails at 4 pm the day before a release. The post-mortem recommends better documentation. The documentation is written, but no one reads it. The same failure recurs six months down the line.
TestWheel addresses this. When any schema changes, the data state is updated once and regenerated across all connected systems.
Provisioning at Pipeline Scale
For organizations running hundreds of parallel test executions in CI, provisioning time becomes a constraint. A provisioning step that takes 90 seconds per suite adds up fast across hundreds of parallel jobs. TestWheel’s generation layer is built to keep provisioning fast enough that it never becomes the bottleneck in your pipeline.
Governance and Audit Trails
Governance requirements in regulated industries apply to test data as well as production data. SOC2 auditors will ask what data was used in testing, how it was generated, and whether it could contain personal information.
A complete audit trail from generation parameters through test execution lets you answer those questions without pulling engineers off active work to reconstruct what happened.
Avoid the failures of bad data with TestWheel’s AI protocols
Most test data problems are the result of a reasonable calculation made repeatedly over many sprints.
The cost of bad test data shows up in production incidents. It impacts regression suites, which pass against data that no longer reflects how the system actually behaves. It triggers cross-system integration failures that are only discovered a few hours before a release. Even though these failures existed throughout, they were distributed across so many teams that nobody flagged them.
AI-driven test data generation helps manage this cost. You still pay upfront. But the investments pay back on every pipeline run.
The one thing that will guarantee failure is treating faster data generation as the goal. Speed without validation creates bad data faster. Treat generation as the first step. Validate what the model produces.
With TestWheel, the process that was breaking your test cycles will actually fix them.



